
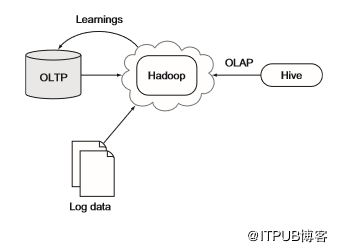
大多数企业的关键数据存在于OLTP数据库中,存储在这些数据库中的数据包含有关用户,产品和其他有用信息。如果要分析此数据,传统方法是定期将该数据复制到OLAP数据仓库中。Hadoop已经出现在这个领域并扮演了两个角色:数据仓库的替代品;结构化、非结构化数据和数据仓库之间的桥梁。图5.8显示了第一个角色,其中Hadoop在将数据导到OLAP系统(BI应用程序的常用平台)之前用作大规模加入和聚合工具。

以Facebook为例,该企业已成功利用Hadoop和Hive作为OLAP平台来处理数PB数据。图5.9显示了类似于Facebook的架构。该体系结构还包括OLTP系统的反馈循环,可用于推送在Hadoop中发现的洞察,例如为用户提供建议。
在任一使用模型中,我们都需要一种将关系数据引入Hadoop的方法,还需要将其输出到关系数据库中。本节,我们将使用Sqoop简化将关系数据输出到Hadoop的过程。
实践:使用Sqoop从MySQL导入数据
Sqoop是一个可用于将关系数据输入和输出Hadoop的项目。它是一个很好的高级工具,封装了与关系数据移动到Hadoop相关的逻辑,我们需要做的就是为Sqoop提供确定输出哪些数据的SQL查询。该技术提供了有关如何使用Sqoop将MySQL中的某些数据移动到HDFS的详细信息。
本节使用Sqoop 1.4.4版本,此技术中使用的代码和脚本可能无法与其他版本的Sqoop一起使用,尤其是Sqoop 2,它是作为Web应用程序实现的。
问题
将关系数据加载到集群中,并确保写入有效且幂等。
解决方案
在这种技术中,我们将看到如何使用Sqoop作为将关系数据引入Hadoop集群的简单机制。我们会介绍将数据从MySQL导入Sqoop的过程,还将介绍使用快速连接器的批量导入(连接器是提供数据库读写访问的特定于数据库的组件)。
讨论
Sqoop是一个关系数据库输入和输出系统,由Cloudera创建,目前是Apache项目。
执行导入时,Sqoop可以写入HDFS、Hive和HBase,对于输出,它可以执行相反操作。导入分为两部分:连接到数据源以收集统计信息,然后触发执行实际导入的MapReduce作业。图5.10显示了这些步骤。

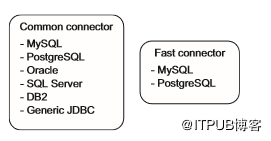
Sqoop有连接器的概念,它包含读写外部系统所需的专用逻辑。Sqoop提供两类连接器:用于常规读取和写入的通用连接器,以及使用数据库专有批处理机制进行高效导入的快速连接器。图5.11显示了这两类连接器及其支持的数据库。
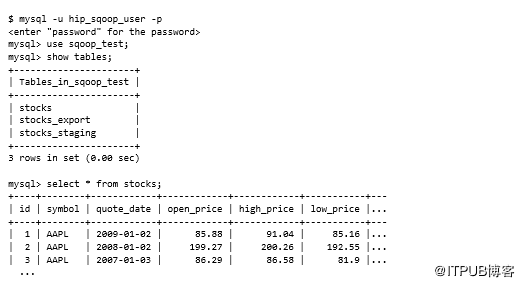
在继续之前,我们需要访问MySQL数据库,并且MySQL JDBC JAR需要可用。以下脚本将创建必要的MySQL用户和模式并加载数据。该脚本创建了一个hip_sqoop_user MySQL用户,并创建了包含三个表的sqoop_test数据库:stocks,stocks_export和stocks_staging。然后,它将stock样本数据加载到表中。所有这些步骤都通过运行以下命令来执行:

这是快速浏览脚本功能:
第一个Sqoop命令是基本导入,在其中指定MySQL数据库和要导出的表连接信息:

MySQL表名称
Linux中的MySQL表名称区分大小写,确保在Sqoop命令中提供的表名使用正确的大小写。
默认情况下,Sqoop使用表名作为HDFS中的目标目录,用于执行导入的MapReduce作业。如果再次运行相同的命令,MapReduce作业将失败,因为该目录已存在。
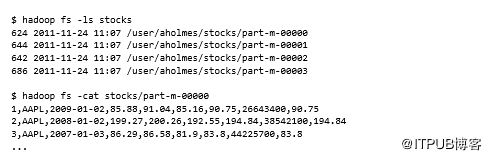
我们来看看HDFS中的stocks目录:
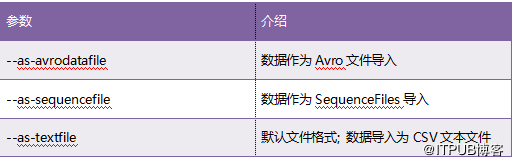
导入数据格式
Sqoop已将数据导入为逗号分隔的文本文件。它支持许多其他文件格式,可以使用表5.6中列出的参数激活它们。
如果要导入大量数据,则可能需要使用Avro等文件格式,这是一种紧凑的数据格式,并将其与压缩结合使用。以下示例将Snappy压缩编解码器与Avro文件结合使用。它还使用--target-dir选项将输出写入表名的不同目录,并指定应使用--where选项导入行的子集。可以使用--columns指定要提取的特定列:
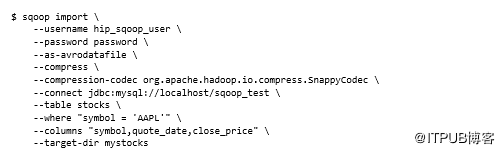
请注意,必须在io.compression.codecs属性下的配置文件core-site.xml中定义在命令行上提供的压缩。Snappy压缩编解码器要求安装Hadoop本机库。有关压缩设置和配置等更多详细信息,请参见第4章,链接见文末。
可以通过引入AvroDump工具来了解Avro文件结构,以了解Sqoop如何布局记录。Sqoop使用Avro的GenericRecord进行记录级存储(有关详细信息,请参阅第3章,链接见文末)。如果针对HDFS中Sqoop生成的文件运行AvroDump,将看到以下内容:

将Sqoop与SequenceFiles结合使用
SequenceFiles难以使用的一个原因是,没有通用的方法来访问SequenceFile中的数据。必须有权访问用于写入数据的Writable类。在Sqoop的情况下,代码可生成此文件,这引入了一个主要问题:如果转移到较新版本的Sqoop,并且该版本修改了代码生成器,那么旧代码生成的类可能无法与SequenceFiles一起使用。需要将所有旧的SequenceFiles迁移到新版本,或者具有可以使用这些SequenceFiles不同版本的代码。由于此限制,不建议将SequenceFiles与Sqoop一起使用。如果正在寻找有关SequenceFiles如何工作的更多信息,请运行Sqoop导入工具并查看在工作目录中生成的stocks.java文件。
可以更进一步,使用--query选项指定整个查询,如下所示:


保护密码
到目前为止,我们一直在命令行中使用明文密码,这是一个安全漏洞,因为主机上的其他用户可以轻松列出正在运行的进程并查看密码。幸运的是,Sqoop有一些机制可以用来避免密码泄露。
第一种方法是使用-P选项,这将导致Sqoop提示输入密码。这是最安全的方法,因为它不需要存储密码,但这意味着无法自动执行Sqoop命令。
第二种方法是使用--password-file选项,可以在其中指定包含密码的文件。请注意,此文件必须存在于已配置的文件系统中(通常可能是HDFS),而不是存在于Sqoop客户端本地磁盘上。你可能希望锁定文件,以便只有你对此文件具有读取权限。 这仍然不是最安全的选项,因为文件系统上的root用户仍然可以窥探文件,除非运行安全级别较高的Hadoop,否则即使非root用户也可以轻松访问。
最后一个选项是使用选项文件。创建一个名为〜/.sqoop-import-opts的文件:

不要忘记锁定文件以避免用户窥探:

然后,我们可以通过--options-file选项将此文件名提供给Sqoop作业,Sqoop将读取文件中指定的选项,这意味着无需在命令行上提供它们:

数据拆分
Sqoop如何在多个mapper之间并行化导入?在图5.10中,我展示了Sqoop的第一步是如何从数据库中提取元数据。它检查导入的表以确定主键,并运行查询以确定表中数据的下限和上限(见图5.12)。Sqoop假设在最小和最大键内的数据接近均匀分布,因为它将delta(最小和最大键之间的范围)按照mapper数量拆分。然后,为每个mapper提供包含一系列主键的唯一查询。
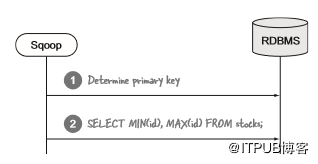
图5.12 确定查询拆分的Sqoop预处理步骤
我们可以将Sqoop配置为使用带有--split-by参数的非主键,这在最小值和最大值之间没有均匀分布的情况下非常有用。但是,对于大型表,需要注意--split-by中指定的列已编制索引以确保最佳导入时间,可以使用--boundary-query参数构造备用查询以确定最小值和最大值。
增量导入
Sqoop支持两种导入类型:追加用于随时间递增的数值数据,例如自动增量键;lastmodified适用于带时间戳的数据。在这两种情况下,都需要使用--check-column指定列,通过--incremental参数指定模式(值必须是append或lastmodified),以及用于通过--last-value确定增量更改的实际值。
例如,如果要导入2005年1月1日更新的stock数据,则执行以下操作:

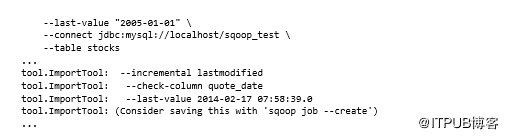
假设还有另一个系统继续写入该表,可以使用此作业的--last-value输出作为后续Sqoop作业的输入,这样只会导入比该日期更新的行。
Sqoop作业和Metastore
可以在命令输出中看到增量列的最后一个值。如何才能最好地自动化可以重用该值的流程?Sqoop有一个作业的概念,可以保存这些信息并在后续执行中重复使用:

执行上述命令会在Sqoop Metastore中创建一个命名作业,该作业会跟踪所有作业。默认情况下,Metastore包含在.sqoop下的主目录中,仅用于自己的作业。如果要在用户和团队之间共享作业,则需要为Sqoop的Metastore安装符合JDBC的数据库,并在发出作业命令时使用--meta-connect参数指定其位置。
在上一个示例中执行的作业创建命令除了将作业添加到Metastore之外没有做任何其他操作。要运行作业,需要显式执行,如下所示:
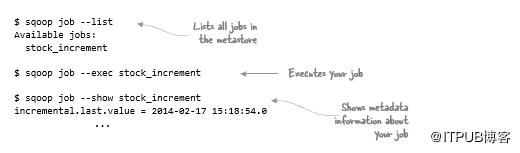
--show参数显示的元数据包括增量列的最后一个值。这实际上是执行命令的时间,而不是表中的最后一个值。如果正在使用此功能,请确保数据库服务器和与服务器(包括Sqoop客户端)交互的任何客户端的时钟与网络时间协议(NTP)同步。
Sqoop将在运行作业时提示输入密码。要使其在自动脚本中运行,需要使用Expect(一种Linux自动化工具)在检测到Sqoop提示输入密码时从本地文件提供密码,可以在GitHub上找到与Sqoop一起使用的Expect脚本,网址为:https://github.com/alexholmes/hadoop-book/blob/master/bin/sqoop-job.exp。
Sqoop作业也可以删除,如下所示:
- $ sqoop job --delete stock_increment
快速MySQL导入
如果想完全绕过JDBC并使用快速MySQL Sqoop连接器进行HDFS的高吞吐量加载,该怎么办?该方法使用MySQL附带的mysqldump实用程序来执行加载。必须确保mysqldump位于运行MapReduce作业的用户路径中。要启用快速连接器,必须指定--direct参数:

快速连接器有哪些缺点? 快速连接器仅适用于文本输出文件 ,指定Avro或SequenceFile,因为导入的输出格式不起作用。
导入到Hive
此技术的最后一步是使用Sqoop将数据导入Hive表。HDFS导入和Hive导入之间的唯一区别是Hive导入有一个后处理步骤,其中创建并加载Hive表,如图5.13所示。
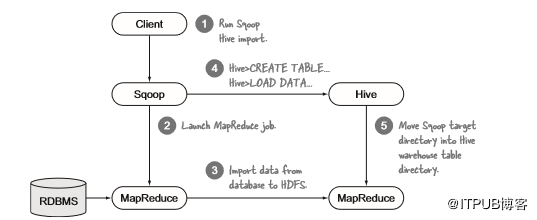
当数据从HDFS文件或目录加载到Hive时,如Sqoop Hive导入的情况(图中的步骤4),Hive将目录移动到其仓库而不是复制数据(步骤5)以提高效率。导入后,Sqoop MapReduce作业写入的HDFS目录将不存在。
Hive导入是通过--hive-import参数触发的。就像快速连接器一样,此选项与--as-avrodatafile和--as -sequencefile选项不兼容:

导入包含Hive分隔符的字符串
如果要导入可以包含任何Hive分隔符(\n,\r和\01字符)的列,则可能会出现下游处理问题。在这种情况下,有两种选择:指定--hive-drop-import-delims,它将删除导入部分的冲突字符,或指定--hive-delims-replacement,它将用不同的字符替换它们。
如果Hive表已存在,则数据将附加到现有表。如果这不是所需的行为,则可以使用--hive-overwrite参数指示应使用导入的数据替换现有表。Sqoop目前仅支持Hive的文本输出,因此LZOP压缩编解码器是最佳选择,因为它可以在Hadoop中拆分(详见第4章)。以下示例显示如何结合使用--hive-overwrite LZOP压缩。为此,我们需要在集群上构建并安装LZOP,因为默认情况下它不与Hadoop(或CDH)捆绑在一起。有关详细信息,请参阅第4章(链接见文末):


最后,我们可以使用--hive-partition-key和--hive-partition-value参数根据要导入的列的值创建不同的Hive分区。例如,如果要按stock名称对输入进行分区,请执行以下操作:

现在,前面的例子无论如何都不是最优的。理想情况下,单个导入将能够创建多个Hive分区。因为仅限于指定单个键和值,所以每个唯一的分区值需要运行一次导入,这很费力。最好导入到未分区的Hive表中,然后在加载后在表上追溯创建分区。
此外,提供给Sqoop的SQL查询还必须注意过滤掉结果,以便仅包含与分区匹配的那些。换句话说,如果Sqoop用符号=“AAPL”更新WHERE子句,那将会很有用。
连续Sqoop执行
如果需要定期安排导入HDFS,Oozie可以进行Sqoop集成,允许定期执行导入和导出。Oozie workflow.xml示例如下:

元素中不支持单引号和双引号,因此如果需要指定包含空格的参数,则需要使用元素:

使用Oozie的Sqoop时的另一个考虑因素是需要为Oozie提供JDBC驱动程序JAR。我们可以将JAR复制到工作流的lib/目录中,也可以使用JAR更新Hadoop安装的lib目录。
总结
显然,要使Sqoop工作,Hadoop集群节点需要能够访问MySQL数据库。常见的错误来源是错误配置或缺少Hadoop节点的连接。登录到其中一个Hadoop节点并尝试使用MySQL客户端连接到MySQL服务器或尝试使用mysqldump实用程序(如果使用的是快速连接器)可能是明智的。
使用快速连接器的另一个重点是,假设mysqldump安装在每个Hadoop节点上,并且位于运行map任务的用户路径中。本节内容的重点是将传统关系数据库的数据导入Hadoop,接下来,我们将从关系存储转换到NoSQL存储—HBase,后者擅长与Hadoop的数据互操作,因为它使用HDFS存储数据。
(注:本文为《Hadoop从入门到精通》大型专题的第五章内容,本专题的其他文章见文末链接,专题的上半部也将于不久之后与大家见面,请持续关注本专题!)
按字母顺序浏览:A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
→我们致力于为广大网民解决所遇到的各种电脑技术问题 如果您认为本词条还有待完善,请 编辑词条


