从node问世以后,就不断被Java的忠实追随者拿来干一些原来只有php、Python等后端语言才能干的事情,例如写个爬虫之类的。对于前端er来说,用上一些好用的轮子,你可能十几行代码就可以写一个crawler哦~
爬虫的思路十分简单:
- 按照一定的规律发送 HTTP 请求获得页面 HTML 源码(必要时需要加上一定的 HTTP 头信息,比如 cookie 或 referer 之类)
- 利用正则匹配或第三方模块解析 HTML 代码,提取有效数据
- 将数据持久化到数据库中
当然爬虫的写法千千万,下面只提供吃瓜群众都能看懂的版本~
*文章目录*
1.1. NPM
1.2. package.json
1.3. crawler.js
2.1. REQUEST
2.2. CHEERIO
*准备阶段* NPM
(npm:趁还没被yarn干掉再续一秒)
首先我们需要通过npm安装两个模块reuqest和cheerio来帮助我们更方便地请求和 解析页面
终端cd到你的文件目录里,先装上,一会儿我再各自讲它们

package.json
装完你可以看到你文件夹里的package.json里已经多了两个依赖项

crawler.js
假设你的爬虫程序主文件名叫crawler.js,我们需要在这个文件里引入request和cheerio这两个模块
js代码为

准备阶段完成后,让我们开始沉迷于学习阶段= =
*学习阶段*REQUEST
request是个非常好用的针对HTTP请求的模块,简言之是对 http.request更高级的封装,口号是——“Simplified HTTP client”
request 这个模块可以帮你下载资料。使用方式:

随便来个例子,假设你觉得你自己真是沉迷于学习无法自拔,是我的迷妹/痴汉一只,你想要随时监控我博客的内容,那你就这样写

不过我建议你们转去搞LV的( ͡° ͜ʖ ͡°)=>群疯之下
(小学妹就不坑LV老师啦,欢迎大家自行寻找他的个人站~)
CHEERIO
cheerio模块可以在服务器端像使用Jquery的方式一样操作Dom结构,许多用法和jquery 的语法基本相同,为服务器特别定制的,快速、灵活、实施的jQuery核心实现。
简言之,是服务器端的鸡块瑞(◕ܫ◕)~
Cheerio 几乎能够解析任何的 HTML 和 XML document,灵活好用,灰常厉害
只需这么用:
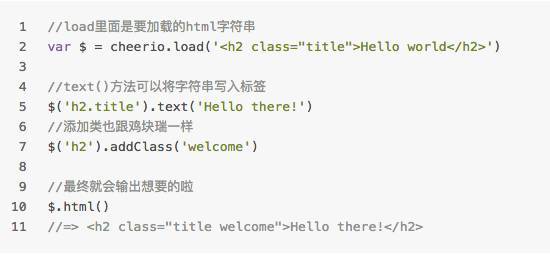
基础知识学习完毕,让我们一起投入到火热的社会主义建设中去~
*建设阶段*
先把request搞上去,明确要爬的页面,我们要爬的是A站的文章区(我不想搞B站,不想被封号TAT)

我们当然不能拍拍手,我们要用cheerio去解析我们刚请求成功的页面

最后爬下来的结果我们把它放在result.json文件里

最后把这句话放在request方法里
最终你的crawler.js看起来是这样
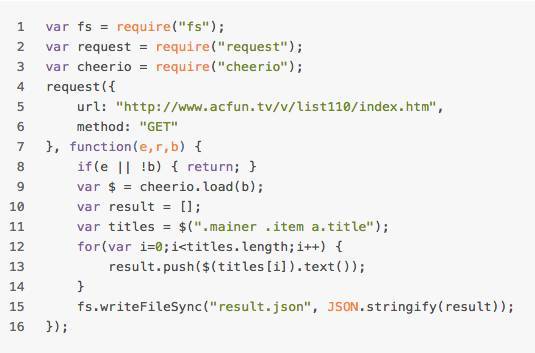
啊~麻麻~我用16行代码就写了个爬虫~╰(°▽°)╯
慢着,我们先来试验下是否能成功
*实验阶段*
cd 到你的目录,敲下激动人心的如下代码
然后观察你的文件夹里是否多了个result.json呢,它看起来应该是如下这样充满了大新闻
result.json

恭嘿累爬虫成功~想要爬到更深入的信息,就自己去看API吧~爬到什么不得了的东西的话,记得分享给我萌哦~
按字母顺序浏览:A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
→我们致力于为广大网民解决所遇到的各种电脑技术问题 如果您认为本词条还有待完善,请 编辑词条


