最近研究了一下抖音的爬虫,目前实现了热门话题和热门音乐下面所有相关视频的爬取,并且我已经将该爬虫打包成了一个 Python 库并发布,名称就叫做 douyin,利用该库可以使用不到 10 行代码完成热门视频的下载、相关音乐的下载以及结构化信息的存储。
本文就来详细介绍一下这个库的用法和一些核心逻辑实现。
在开始介绍之前,我们就先看看这个库能达到怎样的爬取效果吧,这里我们想要爬取的部分是这这样的:
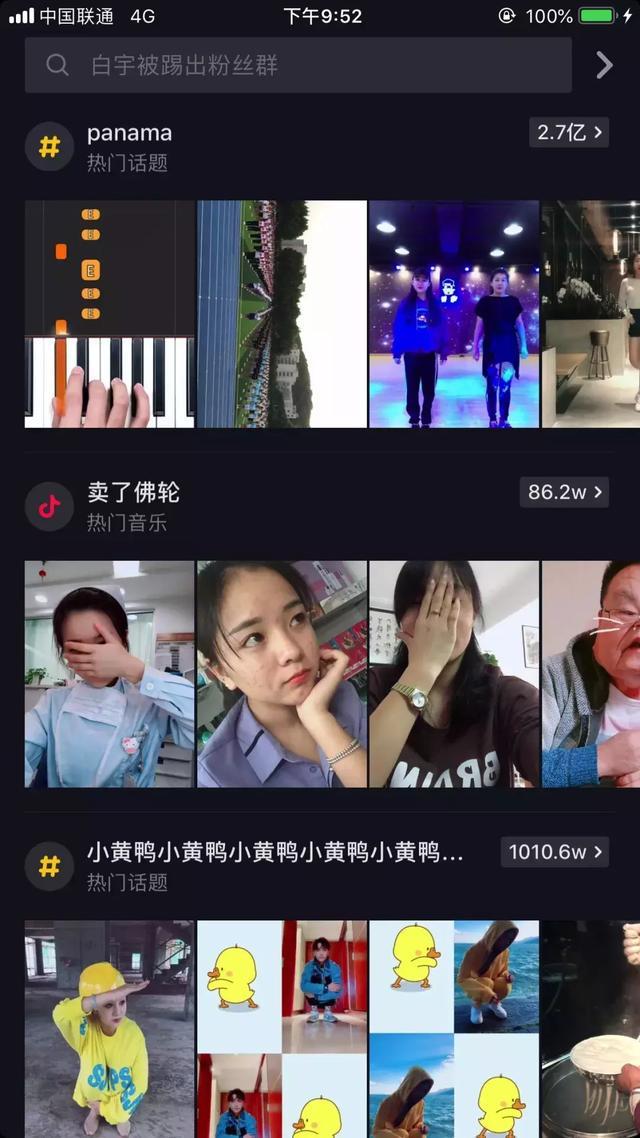
这里是抖音搜索界面热门话题和热门音乐部分,每一个话题或音乐都有着非常高的热度,而且每个热门话题或音乐下面都是相关的抖音视频。
下面我们要做的就是把所有热门话题和音乐下的相关视频都爬取到,并且将爬到的视频下载下来,同时还要把视频所配的音乐也单独下载下来,不仅如此,所有视频的相关信息如发布人、点赞数、评论数、发布时间、发布人、发布地点等等信息都需要爬取下来,并存储到 MongoDB 数据库。
听起来似乎挺繁琐的是吧?其实有了 douyin 这个库,我们不到 10 行代码就可以完成上面的任务了!其 GitHub 地址是:https://github.com/Python3WebSpider/DouYin。
首先第一步我们需要安装一下 douyin 库,命令如下:
pip3 install douyin
使用示例如下:

好,这样就完成了,运行这段代码,即可以完成热门话题、热门音乐下面所有视频和音乐的爬取,并将相关信息存储到 MongoDB 数据库。
另外值得注意的是,在运行这段代码之前首先需要安装好 MongoDB 数据库并成功开启服务,这样才能确保代码可以正常连接数据库并把数据成功存储。
我们看下运行效果:
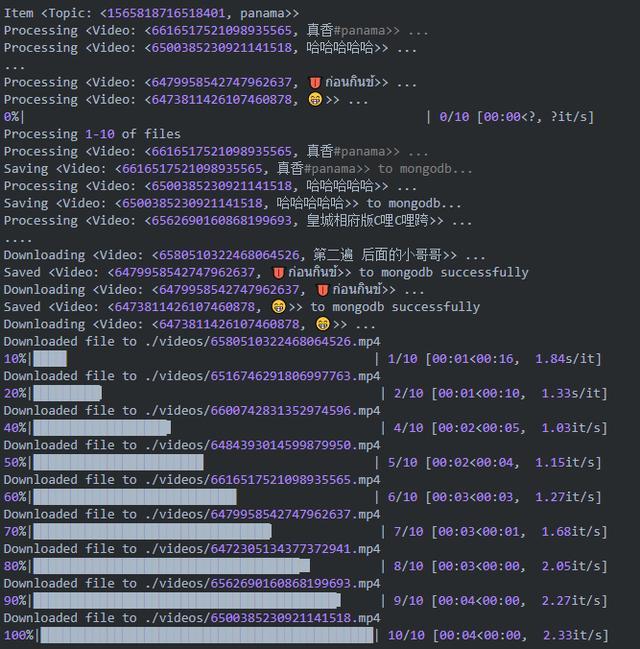
运行截图如下:
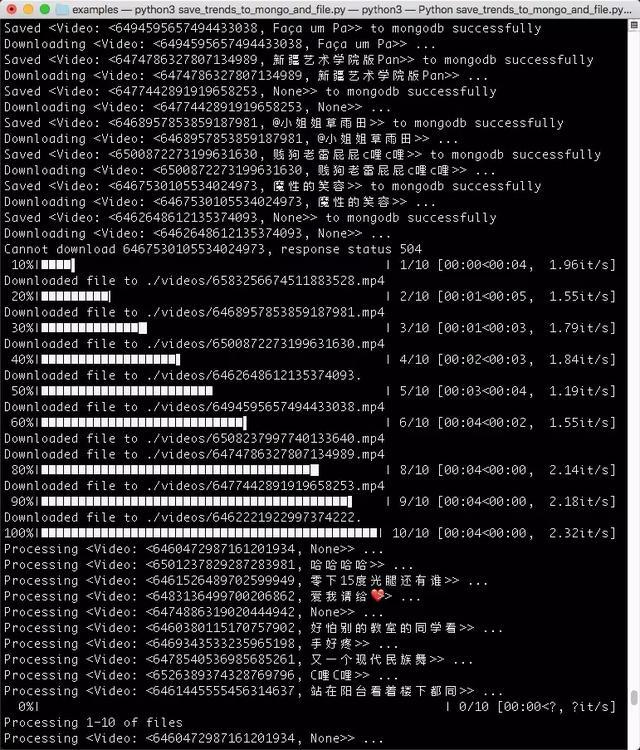
在这里我们可以看到视频被成功存储到了 MongoDB 数据库,并且执行了下载,将视频存储到了本地(音频的的存储没有显示)。
最后我们看下爬取结果是怎样的,下面是爬取到的音频、视频和视频相关信息:
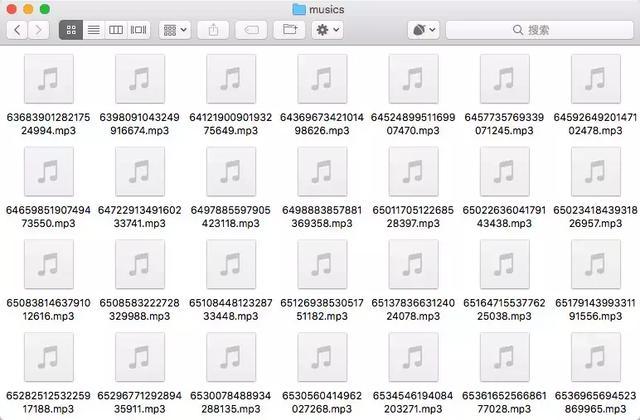
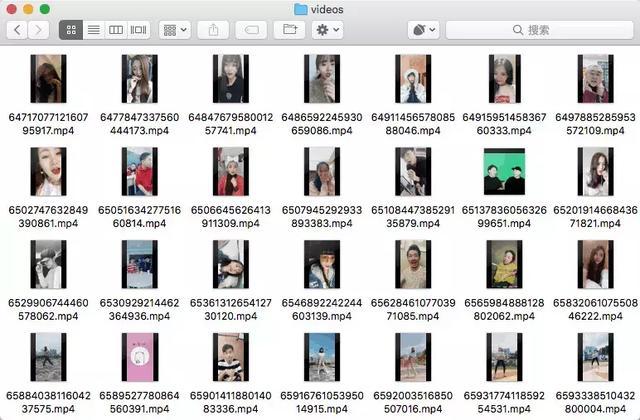
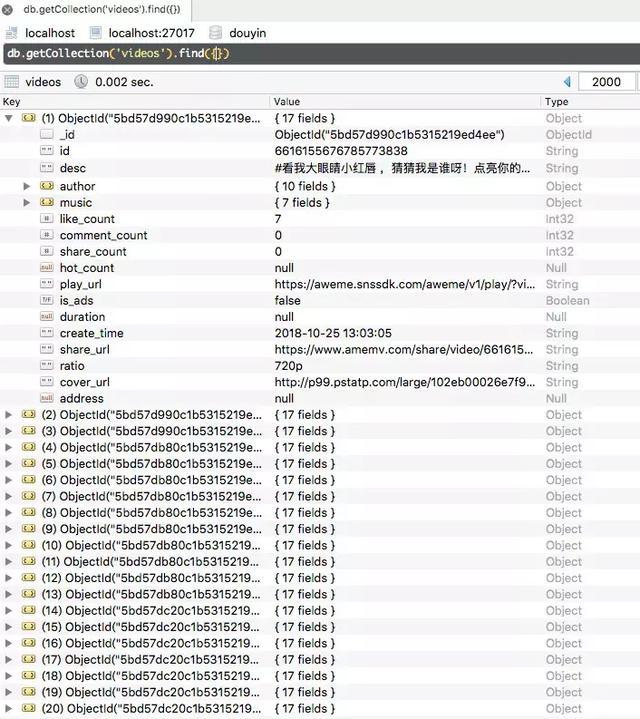
可以看到视频配的音乐被存储成了 mp3 格式的文件,抖音视频存储成了 mp4 文件,另外视频相关信息如视频描述、作者、音乐、点赞数、评论数等等的信息都已经存储到了 MongoDB 数据库,另外里面还包括了爬取时间、视频链接、分辨率等等额外的信息。
对!就是这么简单,通过这几行代码,我们就得到了如上的三部分结果,而这只需要安装 douyin 这个库即可实现。
下面我们来剖析一下这个库的关键技术部分的实现,代码的地址是在:https://github.com/Python3WebSpider/DouYin,在此之前大家可以先将代码下载下来大体浏览一下。
本库依赖的其他库有:
aiohttp:利用它可以完成异步数据下载,加快下载速度。
dateparser:利用它可以完成任意格式日期的转化。
motor:利用它可以完成异步 MongoDB 存储,加快存储速度。
requests:利用它可以完成最基本的 HTTP 请求模拟。
tqdm:利用它可以进行进度条的展示。
下面我就几个部分的关键实现对库的实现进行代码说明。
数据结构定义
如果要做一个库的话,一个很重要的点就是对一些关键的信息进行结构化的定义,使用面向对象的思维对某些对象进行封装,抖音的爬取也不例外。
在抖音中,其实有很多种对象,比如视频、音乐、话题、用户、评论等等,它们之间通过某种关系联系在一起,例如视频中使用了某个配乐,那么视频和音乐就存在使用关系;比如用户发布了视频,那么用户和视频就存在发布关系,我们可以使用面向对象的思维对每个对象进行封装,比如视频的话,就可以定义成如下结构:
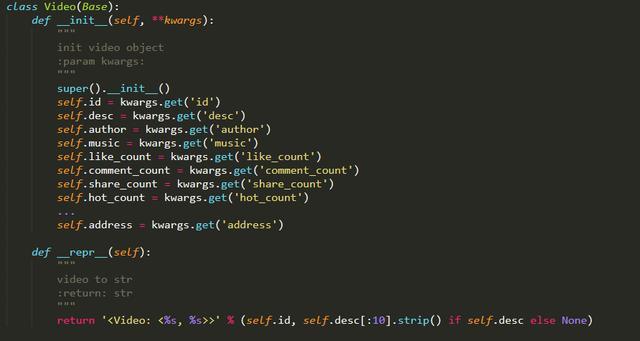
这里将一些关键的属性定义成 Video 类的一部分,包括 id 索引、desc 描述、author 发布人、music 配乐等等,其中 author 和 music 并不是简单的字符串的形式,它也是单独定义的数据结构,比如 author 就是 User 类型的对象,而 User 的定义又是如下结构:
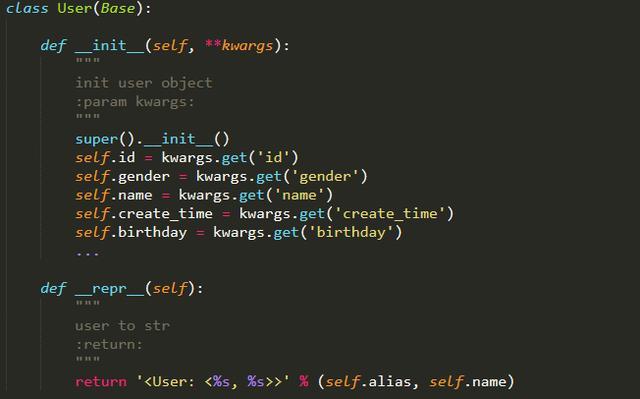
所以说,通过属性之间的关联,我们就可以将不同的对象关联起来,这样显得逻辑架构清晰,而且我们也不用一个个单独维护字典来存储了,其实这就和 Scrapy 里面的 Item 的定义是类似的。
请求和重试
实现爬取的过程就不必多说了,这里面其实用到的就是最简单的抓包技巧,使用 Charles 直接进行抓包即可。抓包之后便可以观察到对应的接口请求,然后进行模拟即可。
所以问题就来了,难道我要一个接口写一个请求方法吗?另外还要配置 Headers、超时时间等等的内容,那岂不是太费劲了,所以,我们可以将请求的方法进行单独的封装,这里我定义了一个 fetch 方法:

这个方法留了一个必要参数,即 url,另外其他的配置我留成了 kwargs,也就是可以任意传递,传递之后,它会依次传递给 requests 的请求方法,然后这里还做了异常处理,如果成功请求,即可返回正常的请求结果。
定义了这个方法,在其他的调用方法里面我们只需要单独调用这个 fetch 方法即可,而不需要再去关心异常处理,返回类型了。
好,那么定义好了请求之后,如果出现了请求失败怎么办呢?按照常规的方法,我们可能就会在外面套一层方法,然后记录调用 fetch 方法请求失败的次数,然后重新调用 fetch 方法进行重试,但这里可以告诉大家一个更好用的库,叫做 retrying,使用它我们可以通过定义一个装饰器来完成重试的操作。
比如我可以使用 retry 装饰器这么装饰 fetch 方法:

这里使用了装饰器的四个参数:
stop_max_attempt_number:最大重试次数,如果重试次数达到该次数则放弃重试。
wait_random_min:下次重试之前随机等待时间的最小值。
wait_random_max:下次重试之前随机等待时间的最大值。
retry_on_exception:判断出现了怎样的异常才重试。
这里 retry_on_exception 参数指定了一个方法,叫做 need_retry,方法定义如下:
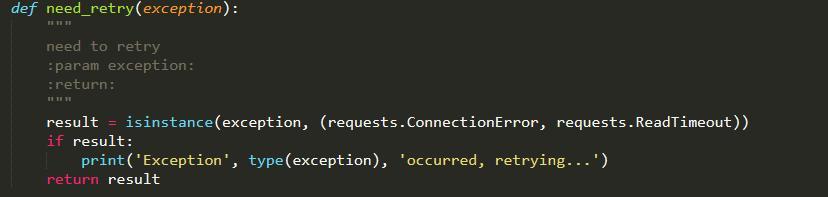
这里判断了如果是 requests 的 Connecti 和 ReadTimeout 异常的话,就会抛出异常进行重试,否则不予重试。
所以,这样我们就实现了请求的封装和自动重试,是不是非常 Pythonic?
为了下载视频,我们需要设计一个下载处理器来下载已经爬取到的视频链接,所以下载处理器的输入就是一批批的视频链接,下载器接收到这些链接,会将其进行下载处理,并将视频存储到对应的位置,另外也可以完成一些信息存储操作。
在设计时,下载处理器的要求有两个,一个是保证高速的下载,另一个就是可扩展性要强,下面我们分别来针对这两个特点进行设计:
高速下载,为了实现高速的下载,要么可以使用多线程或多进程,要么可以用异步下载,很明显,后者是更有优势的。
扩展性强,下载处理器要能下载音频、视频,另外还可以支持数据库等存储,所以为了解耦合,我们可以将视频下载、音频下载、数据库存储的功能独立出来,下载处理器只负责视频链接的主要逻辑处理和分配即可。
为了实现高速下载,这里我们可以使用 aiohttp 库来完成,另外异步下载我们也不能一下子下载太多,不然网络波动太大,所以我们可以设置 batch 式下载,可以避免同时大量的请求和网络拥塞,主要的下载函数如下:
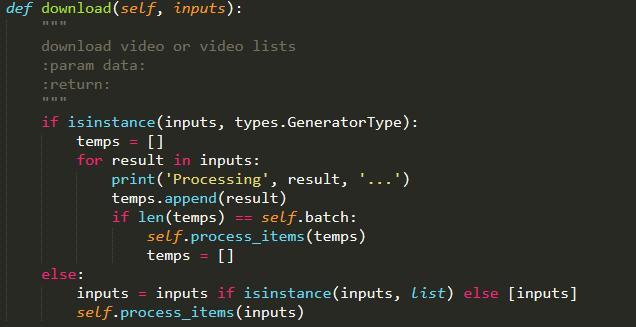
这个 download 方法设计了多种数据接收类型,可以接收一个生成器,也可以接收单个或列表形式的视频对象数据,接着调用了 process_items 方法进行了异步下载,其方法实现如下:
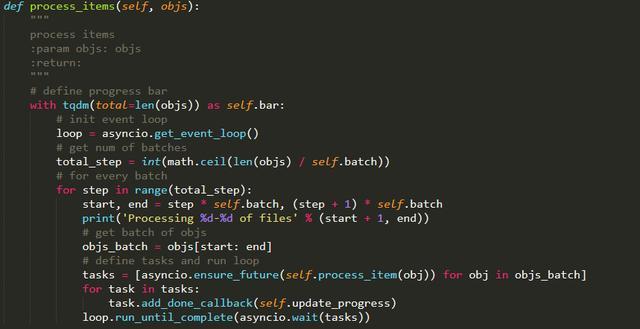
这里使用了 asyncio 实现了异步处理,并通过对视频链接进行分批处理保证了流量的稳定性,另外还使用了 tqdm 实现了进度条的显示。
我们可以看到,真正的处理下载的方法是 process_item,这里面会调用视频下载、音频下载、数据库存储的一些组件来完成处理,由于我们使用了 asyncio 进行了异步处理,所以 process_item 也需要是一个支持异步处理的方法,定义如下:
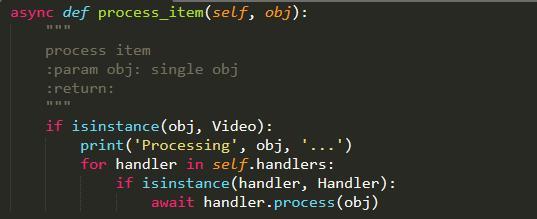
这里我们可以看到,真正的处理逻辑都在一个个 handler 里面,我们将每个单独的功能进行了抽离,定义成了一个个 Handler,这样可以实现良好的解耦合,如果我们要增加和关闭某些功能,只需要配置不同的 Handler 即可,而不需要去改动代码,这也是设计模式的一个解耦思想,类似工厂模式。
刚才我们讲了,Handler 就负责一个个具体功能的实现,比如视频下载、音频下载、数据存储等等,所以我们可以将它们定义成不同的 Handler,而视频下载、音频下载又都是文件下载,所以又可以利用继承的思想设计一个文件下载的 Handler,定义如下:

这里我们还是使用了 aiohttp,因为在下载处理器中需要 Handler 支持异步操作,这里下载的时候就是直接请求了文件链接,然后判断了文件的类型,并完成了文件保存。
视频下载的 Handler 只需要继承当前的 FileHandler 即可:

这里其实就是加了类别判断,确保数据类型的一致性,当然音频下载也是一样的。
上面介绍了视频和音频处理的 Handler,另外还有一个存储的 Handler 没有介绍,那就是 MongoDB 存储,平常我们可能习惯使用 PyMongo 来完成存储,但这里我们为了加速,需要支持异步操作,所以这里有一个可以实现异步 MongoDB 存储的库,叫做 Motor,其实使用的方法差不太多,MongoDB 的连接对象不再是 PyMongo 的 MongoClient 了,而是 Motor 的 AsyncIOMotorClient,其他的配置基本类似。
在存储时使用的是 update_one 方法并开启了 upsert 参数,这样可以做到存在即更新,不存在即插入的功能,保证数据的不重复性。
整个 MongoDB 存储的 Handler 定义如下:
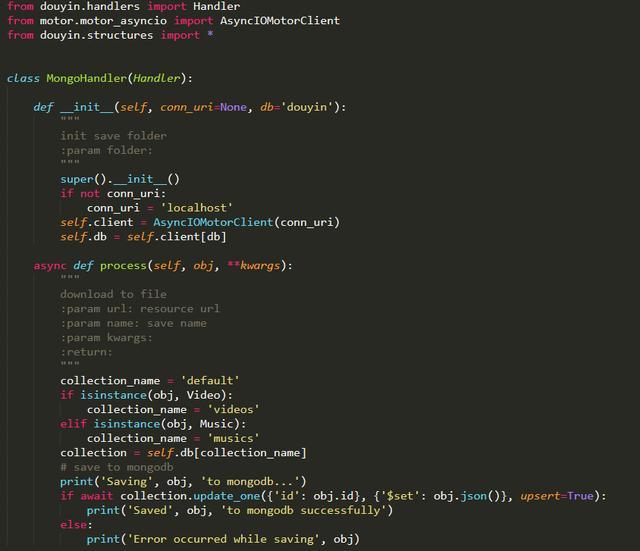
可以看到我们在类中定义了 AsyncIOMotorClient 对象,并暴露了 conn_uri 连接字符串和 db 数据库名称,可以在声明 MongoHandler 类的时候指定 MongoDB 的链接地址和数据库名。
同样的 process 方法,这里使用 await 修饰了 update_one 方法,完成了异步 MongoDB 存储。
好,以上便是 douyin 库的所有的关键部分介绍,这部分内容可以帮助大家理解这个库的核心部分实现,另外可能对设计模式、面向对象思维以及一些实用库的使用有一定的帮助。
本文介绍了一个可以用来爬取抖音热门视频的 Python 库,并介绍了该库的基本用法和核心部分实现,希望对大家有所帮助。
按字母顺序浏览:A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
→我们致力于为广大网民解决所遇到的各种电脑技术问题 如果您认为本词条还有待完善,请 编辑词条


