摘要: 这是如何提高阿里云上应用的可用性系列文章的第二篇,第一篇传送门。 在单体应用时代,最大的问题是如何解决数据库瓶颈,而微服务之下,一个大应用被拆分成了几十个甚至上百个微服务,数据访问的压力被传导到了服务之间的网络,服务强弱依赖,服务雪崩等各种问题随之而来,那么如何保障服务的可用性以及整个应用的健壮性.
这是如何提高阿里云上应用的可用性系列文章的第二篇,第一篇传送门。
在单体应用时代,最大的问题是如何解决数据库瓶颈,而微服务之下,一个大应用被拆分成了几十个甚至上百个微服务,数据访问的压力被传导到了服务之间的网络,服务强弱依赖,服务雪崩等各种问题随之而来,那么如何保障服务的可用性以及整个应用的健壮性呢?常见的做法包括:
程序员和女朋友约会在楼下等她的时候一般都会约定 “等你30分钟啊”, 这就是一种超时约定,如果等了半小时女朋友还没有下来,该怎么办?一般有服务治理意识的程序员都会选择超时退出及时止损(不知道这是不是程序员没有女朋友的原因之一)
在应用设计中,为避免集群雪崩或资源耗尽,一切调用都应该设置超时时间,包括RPC/DB/缓存,服务端超时是必选配置。在实际的电商实际场景中,一般服务级别的超时时间通常会设置在100ms~300ms之间。
超时的设定需要注意一个问题就是超时的传递问题, 假设服务A调用服务B,A的超时设定为100ms,B为300ms,那么这个设定就是有问题,因为一旦B的调用时间超过了100ms,A无论如何都会超时,而B的继续调用就会成为一种资源浪费,而在特别复杂的服务依赖关系中,超时的设定一定要考虑传递的问题
当程序员给喜欢的女孩子表白被拒绝了怎么办,一般可以做出万分痛苦状接一句“要不要再考虑一下”,这就是一种重试,在服务调用中,重试就是当对服务端的调用出现异常或者错误时,自动的再次发起调用请求,可见这种方式在服务端出现偶发性抖动或者网络出现抖动的时候可以比较好的提高服务调用的成功率,但同时,如果服务端处在出现故障的边缘时,也有可能成为压垮骆驼的最后一根稻草,所以在生产环境中一定要慎用
家里面使用的保险丝就是一种典型的熔断,一旦电流过大的时候,就是断开以保护整个电路,在程序设计中,一旦服务端的调用的异常或者错误比例超过一定的阈值时,就停止对此服务的调用,此时处于close状态,经过一段时间的熔断期后会尝试重新发起调用,此时处于close-open状态,如果调用成功则放开调用,切换到open状态,否则继续回到close状态
远洋大船的内部都会设计多个水密仓,这样一旦事故出现船体破损,也可以把影响控制在水密仓级别而不至于整个船沉默,这就是一种隔离策略,在程序设计中,为了达到资源隔离和故障隔离,通常有两种做法,一种是通过线程池来进行隔离,对于不同类型资源新建不同的线程池,然后通过设置线程池的大小和超时时间来起到隔离资源使用的效果,但是这种方式由于需要新建线程池,对于资源开销比较大,另外一种方式就是通过观察线程的信号量也就是同类型资源的线程数,当超过相应的阈值时快速拒绝新的资源请求。
本质上这两种方式都是对于超出服务提供能力的请求进行限制,区别是限流的话是立刻拒绝,而流控是让请求进行排队,这种方式对于流量的削峰填谷有着比较好的效果
以上的这些能力一般都会在微服务框架中集成提供,如阿里的Dubbo以及Spring Cloud的Hystrix,通过引入jar包在代码中需要增强的地方加入添加相应的高可用代码,需要在应用系统设计之初就充分考虑进去, 后期业务新增或变更时也需及时维护
接下来随之而来的一个问题就是如何测试验证这些高可用措施是有效的?阈值的设置是否合理?
常用的做法有两个:
压测
通过在云端模拟大量的用户请求来测试应用系统面对突发流量的能力和进行容量规划,这里介绍一款阿里云的PTS产品,可以在云端模拟百万并发,以此可以检测各链路是否有限流降级的措施,是否设置合理-传送门。
故障演练
故障演练是一种比较新的高可用测试的方式,通过软件层面模拟各种可能出现的故障,观察应用系统对于故障的隔离和降级能力。 这一专门的领域称之为Chaos engineering, 在阿里内部,通过故障演练平台,每天都在进行着各种类型的故障演练,这些故障包括操作系统层面的故障如进程意外退出,CPU内存飚高, 也包括网络层面的故障如网络延迟丢包,DNS解析错误, 还包括了应用服务层面的故障如服务接口延迟,异常返回等。通过这种方式可以比较有效的验证应用的高可用能力,找到潜在风险问题。
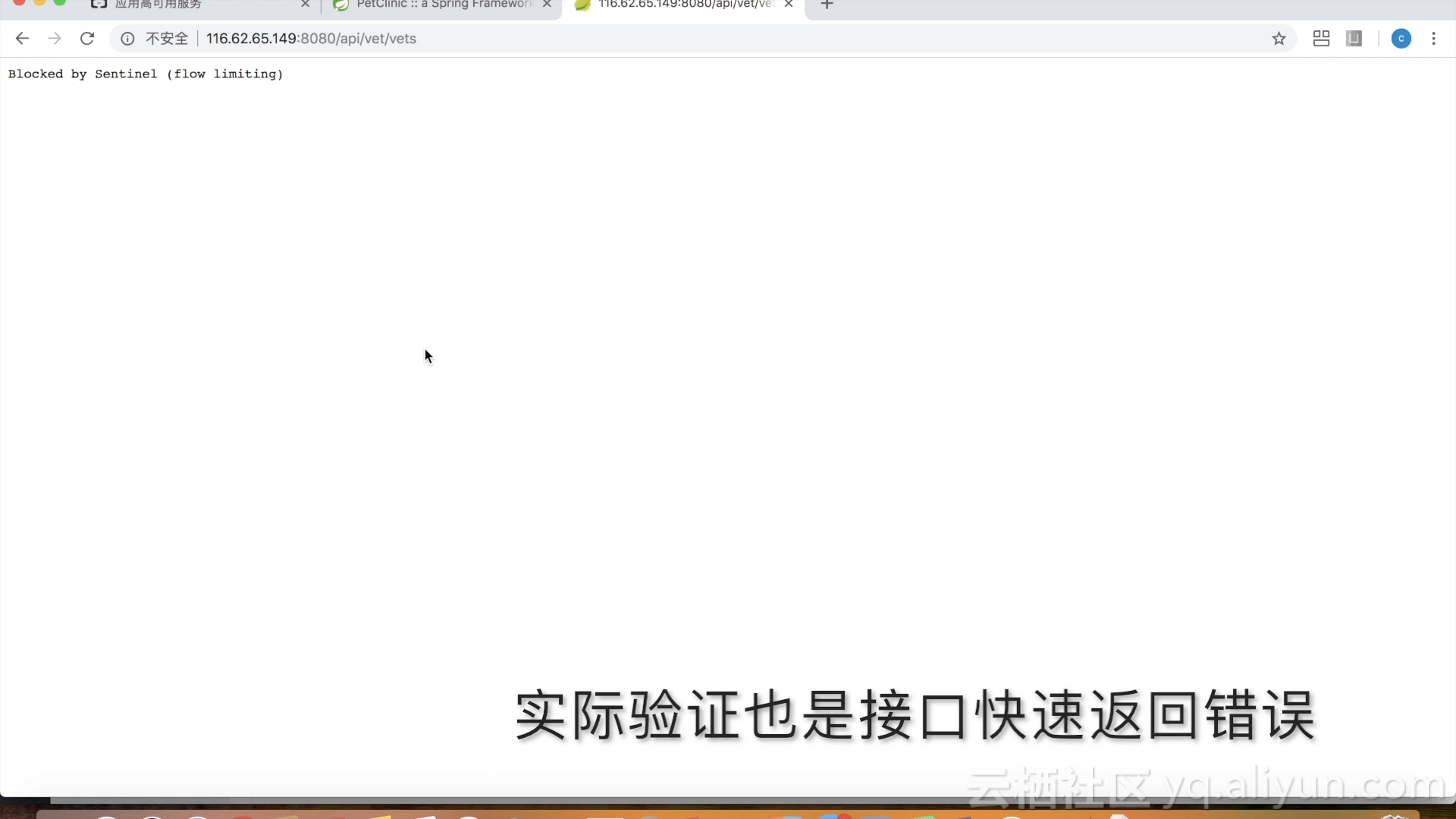
当然对于种种原因没有集成高可用框架,也没有自己搭建故障演练平台的各位同学,阿里云推出了应用高可用服务这一业界首款快速提高应用高可用能力的SaaS产品,来自于多年双十一稳定性保障的经验,具有无需修改代码,全界面操作和性能稳定的特点,下面举例示意如何给云上的应用添加限流和降级的能力(传送门:如何接入应用高可用服务)
对关键接口进行限流


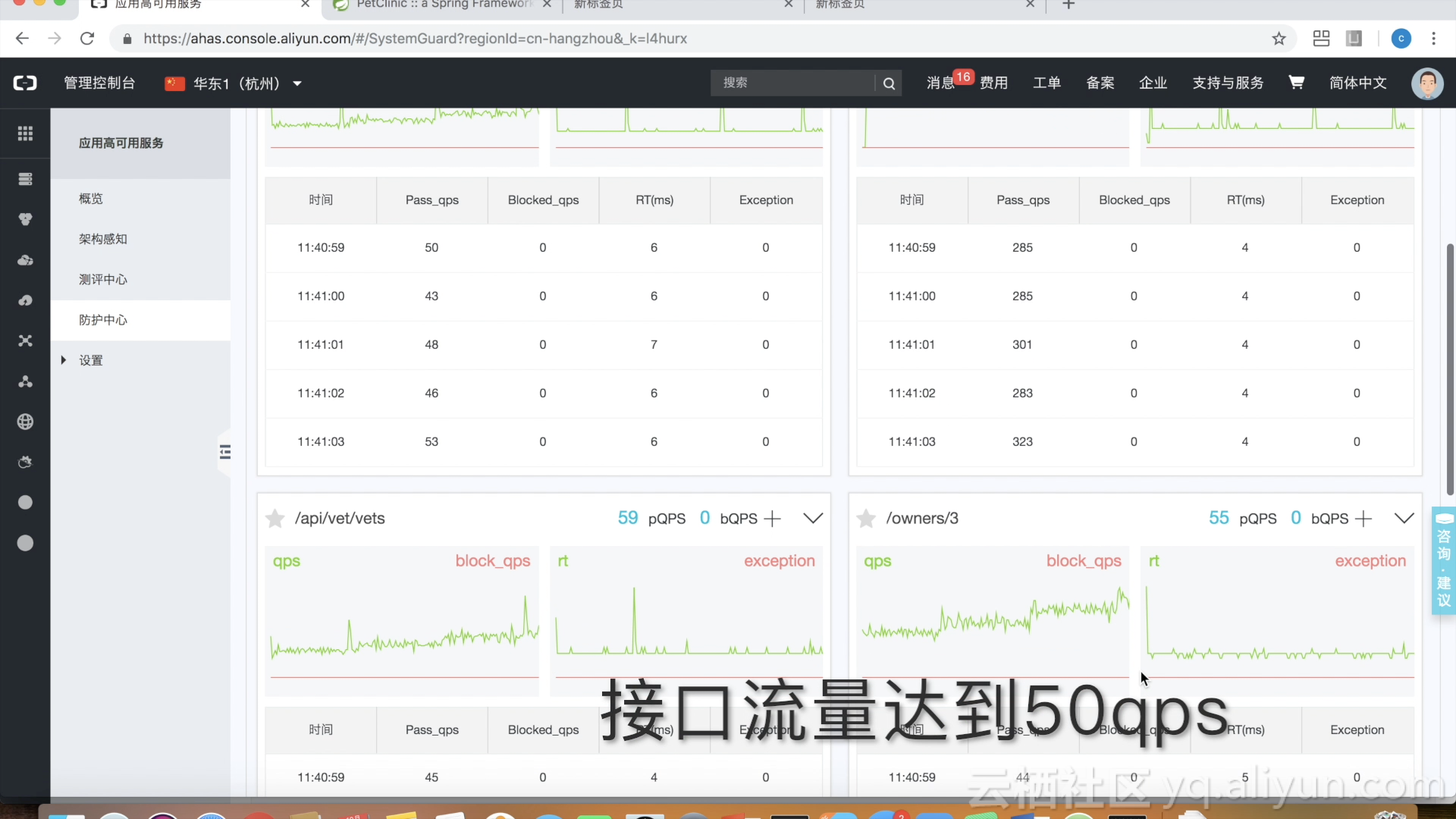
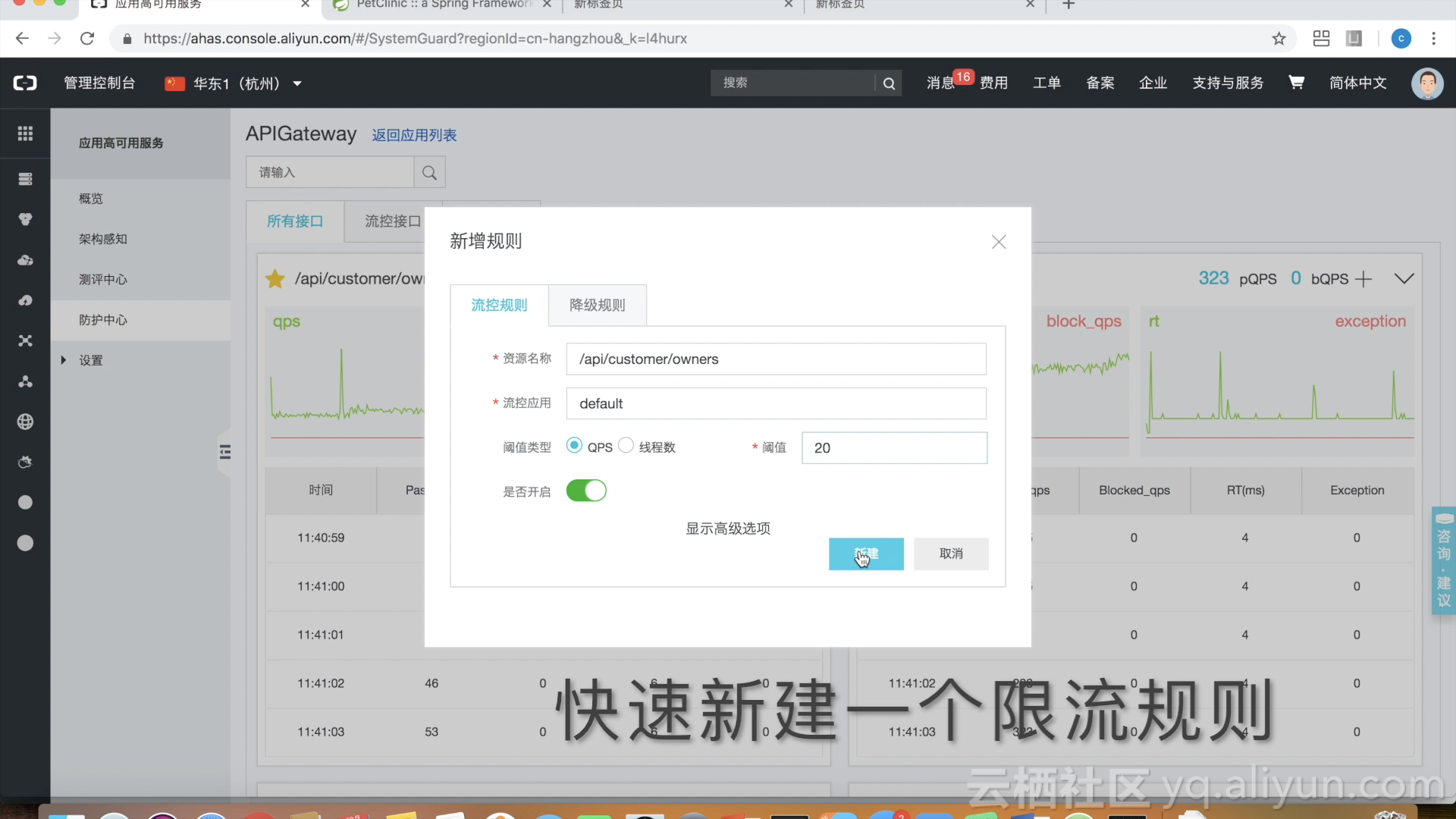


对非关键业务进行降级处理
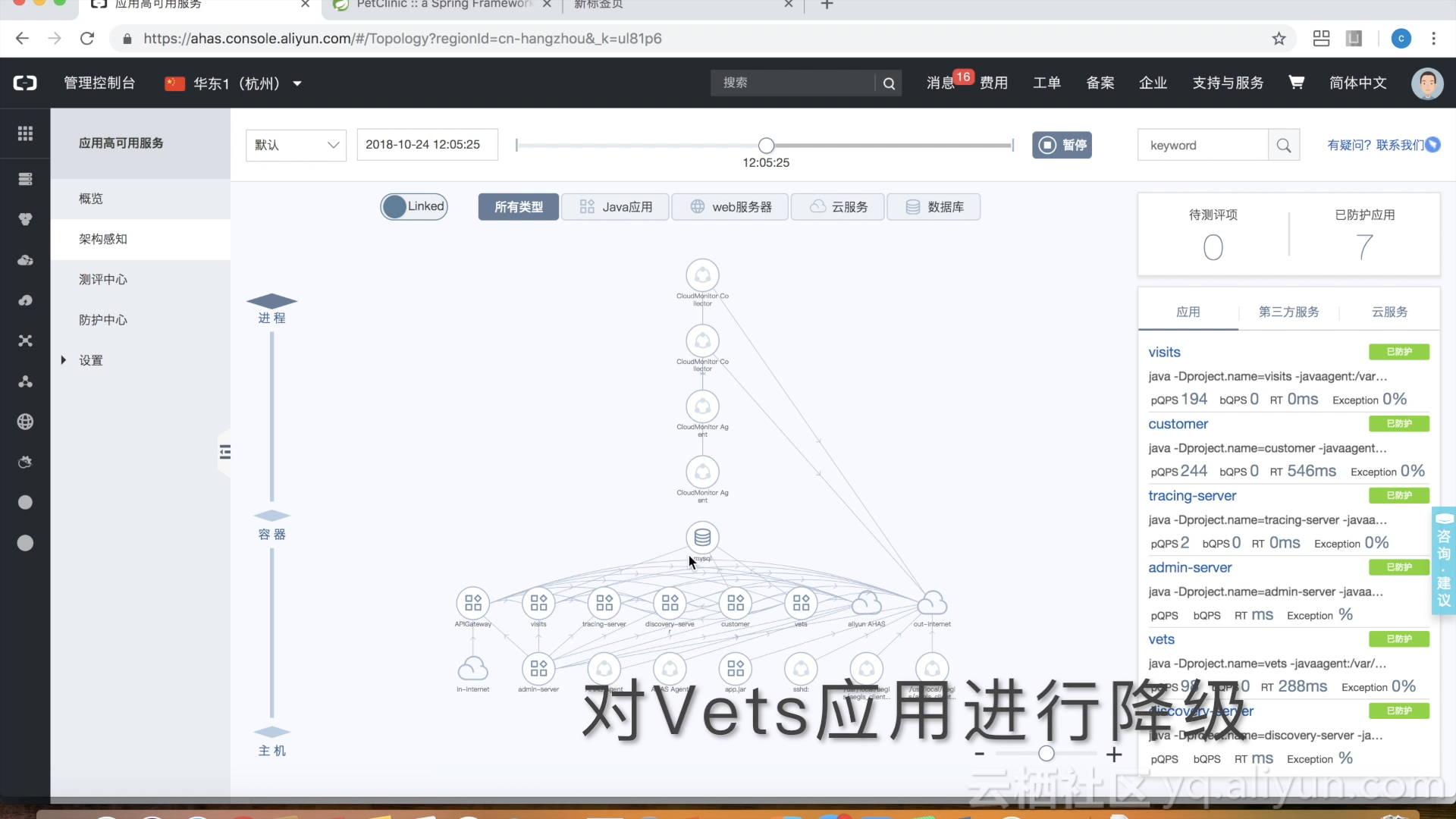

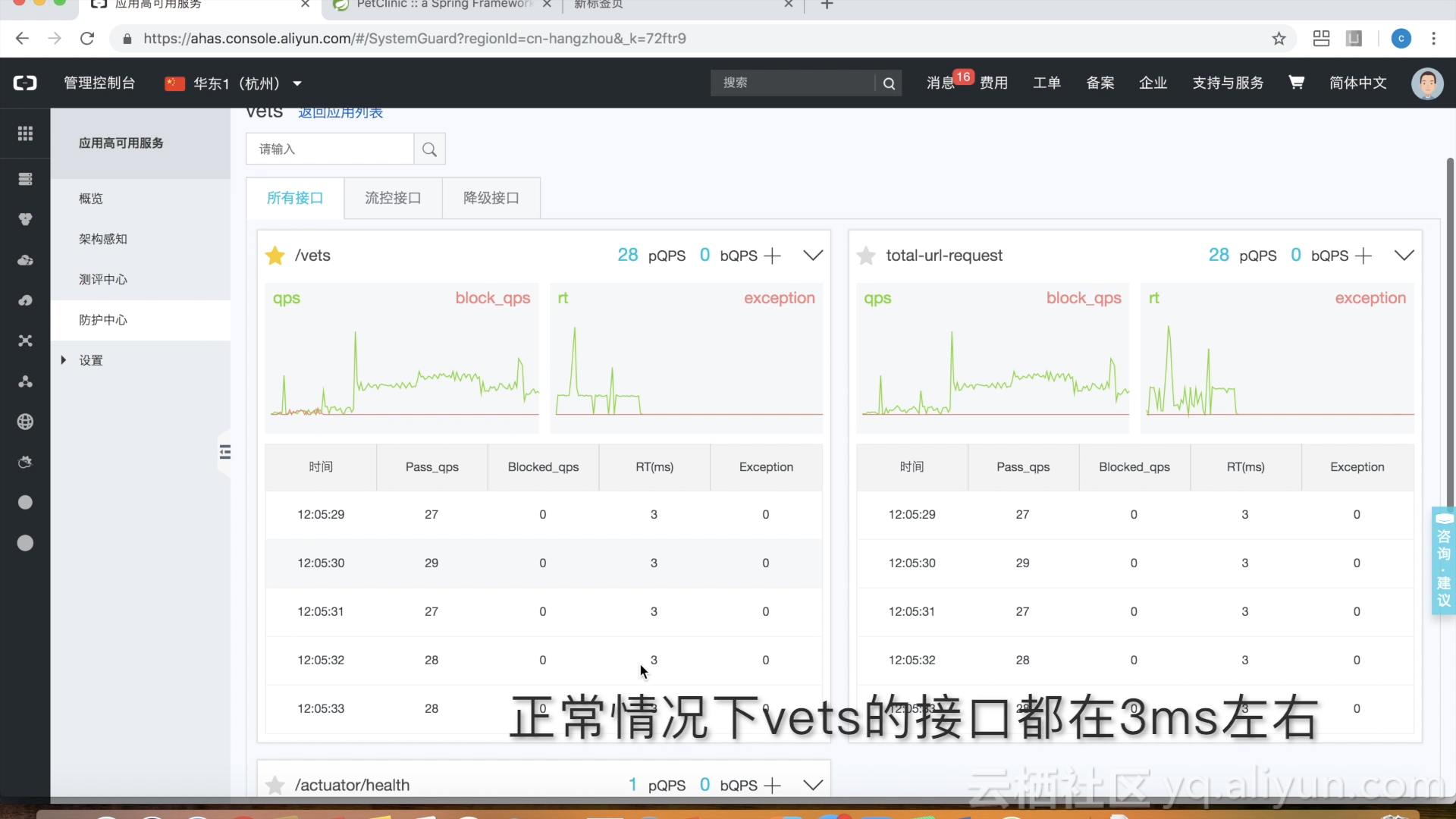






作者:中间件小哥
按字母顺序浏览:A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
→我们致力于为广大网民解决所遇到的各种电脑技术问题 如果您认为本词条还有待完善,请 编辑词条


